How We Work: Managing the NaCl Podcast With GitHub
We’re probably the first webscale podcast. Let us guide you through our story.


As (probably) the world's first webscale, devops podcast, the creators of NaCl had to think big in terms of how we work and collaborate. We need to operate in a transparent, flexible and agile manner in order to work well with all of our stakeholders. In this article we'll demonstrate how GitHub is at the heart of all of this.
(NB this is actually a semi-serious article from here on out. We did some rather interesting things with GitHub and Jekyll).
The podcast feed
The podcast feed file (feed.xml) is statically generated for GitHub Pages (our publishing platform) using vanilla Jekyll.
The feed template iterates over every episode file we've stored and formats it into an XML file that matches the iTunes podcast feed format. This file contains information like the list of episodes, where each audio file is stored, if the episode features naughty words, and when it was released. The feed file is the minimum amount of data to describe an entire podcast.
Each episode file is stored in the _episodes/ directory. They are Markdown formatted text files, with episode metadata stored in the front matter. Check out the source code for our third episode as an example:
---
title: "Spaghetti"
date: 2019-07-10T18:00:00Z
audio_file: https://storage.googleapis.com/static.nacl.bell.wtf/episodes/3-spaghetti.m4a
audio_type: audio/x-m4a
audio_length: 43008
duration: 640
season: 1
episode: 3
description: Guest Hugh Rawlinson joins us to discuss his gripes about Italian style cooking.
guid: nacl/0d764256-9eaa-11e9-8337-876cf44478f3
---
Hugh can be found on Twitter as
[@JCheesemonger](https://twitter.com/JCheesemonger), or
[@HughRawlinson](https://twitter.com/hughrawlinson).A couple of these fields are a little bit tricky to fill out, and really ought to be automated at some point (we could even use GitHub Actions).
audio_filepoints to the actual audio file of this episode.audio_lengthis the file size, in bytes.durationis the audio length, in seconds.guidis just a randomly generated string which is unique for each episode. This is what allows podcast apps/aggregators to distinguish separate episodes, even if you rename it or change the release date.
You might be wondering why we store our episodes like this?
- It's version controlled so we can easily rollback changes if needed.
- It's open source so others can use our work.
- It's easier to read than an XML document.
- We can use these files to display episodes as web pages.
The episode lifecycle
The lifecycle of a NaCl episode looks like this:
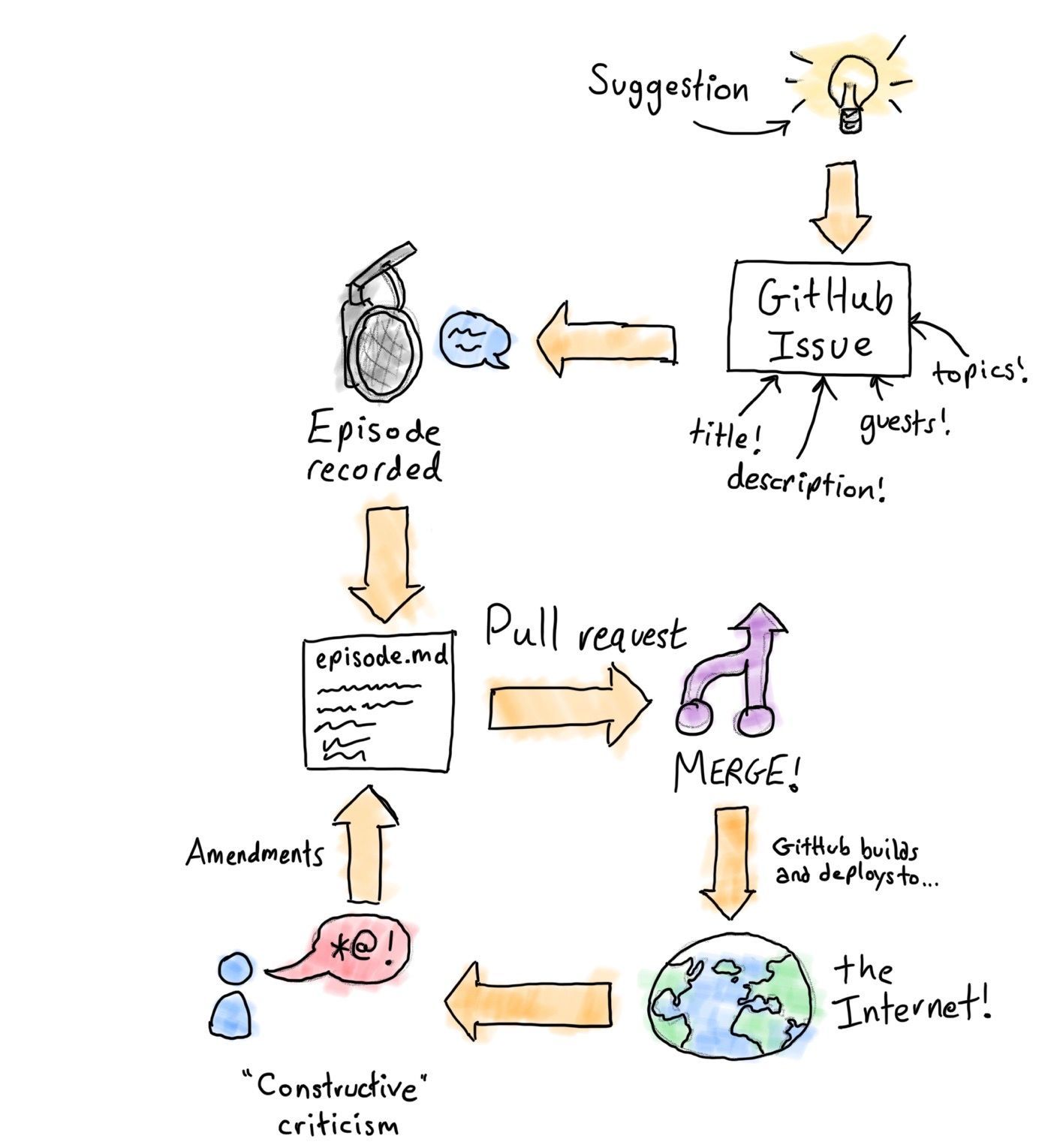
Idea
We begin with an idea for an episode. This is either created by us, the podcast makers, or suggested by a listener through our suggestions form. Both methods result in a GitHub issue created, that follows a predefined template, including a checklist of things we need to do to create the episode.
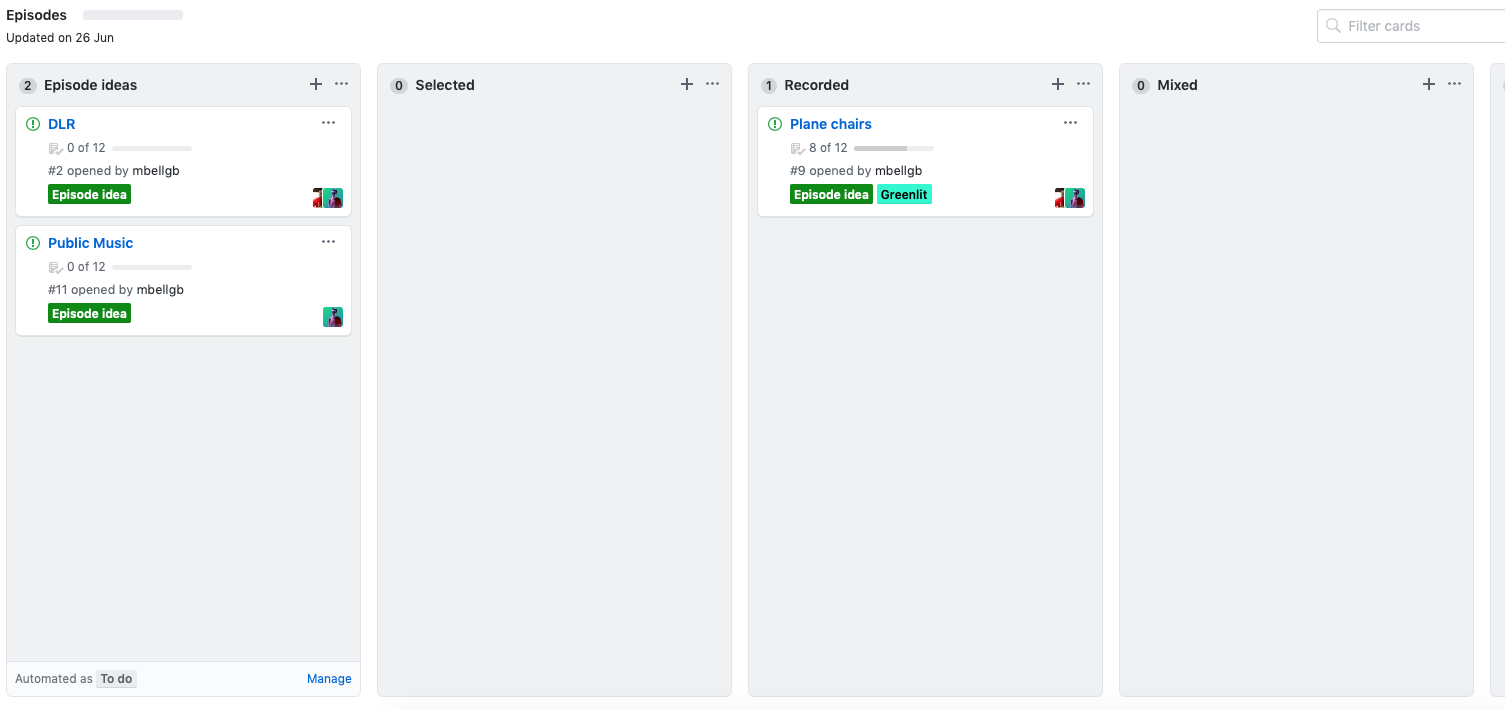
At the same time, we add this issue to our project board of episodes. This allows us to track progress from inception to release. Is this overkill? Yes it probably is. We can even tag in guests into the issue so that they can follow the progress of the episode.
Record and prepare release
The next thing to do is to actually go and record the damn episode. This happens in a super secret location, and we use the power of a popular communication API to connect and record calls with our guests. We've built it in a way so that they don't need any equipment to record, they just need to be able to take a phone call.
The only downside to this is that me and Abdul need to share a pair of AirPods.
Now that we've recorded the episode, we use an intricate and proprietary combination of micro SD cards, adapters, dongles, and Abdul's iPad, to transfer the audio files from the studio to our beloved editor, Harshpal. When he has done his magic, he sends us the mixed podcast episode audio.
The next couple of steps need to be automated really badly. The file is uploaded to Google Cloud Storage, and file size in bytes and duration in seconds is captured (using ffmpeg or similar) and added to the episode markdown file, along with the public URL of the episode.
PR and release

We can finally raise a pull request. The editors are requested for review to ensure the quality of the name and description, before the change is merged and the episode is added to our podcast feed and to our website. Over the next couple of hours, all of the major podcast providers (such as Spotify) will refresh their feeds to include the latest episode, and y'all will get an extra bit of salt in your life.
Where next?
Our work is never done. There's a few things we can add to extend our vision further. The first thing is to set up continuous integration via GitHub Actions. Being able to allow version control to set GUIDs and audio metadata would save us so much time when preparing new episodes. Another thing we could do is to use Jekyll to generate an iCal file for our recording calendar. This will come sooner than later...